Promotion testing provides valuable feedback for marketers. Different offers and presentations can be introduced to small test audiences, with varying product messaging, packaging or media. Control groups allow promotion results to be more carefully monitored, analyzed and compared for both effectiveness and customer preference information.
But the real purpose of testing is assessing the effectiveness of promotions’ ability to generate incremental profit and qualify – monetize – new business opportunities. The true goal is to identify which offers perform best to which groups of people, and to establish, cost effectively, what business expectations for marketing should be. These expectations will find their way into the current forecast and/or next year’s business plan, and objectives will be established in part based on the results of the tests.
Therefore it is particularly important that these expectations are accurate and stem from reasonable conclusions. This places significant emphasis on the interpretation of test results.
Most tests incorporate a control group that measures the response lift against a test promotion. The control may receive the standard promotion, or no promotion at all. Such a two-cell effort can be fairly easy to interpret, and results reasonably straightforward, assuming a suitable confidence interval is chosen around response and purchase value.
Imagine, though, the consternation the following hypothetical case might cause. In this example, results for five tests and a control are presented based on response rate and the average profit per response. The example has been contrived intentionally so that the test group with the lowest response rate – Test 3 = 8.8% – also has the highest profit – $13.69 – per response.
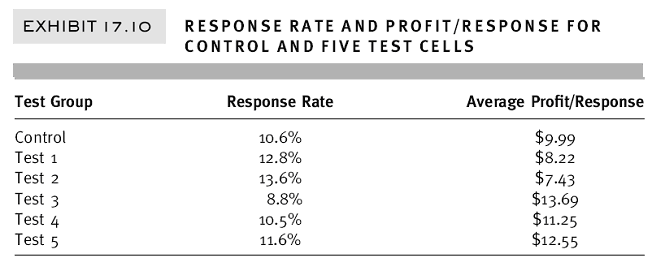 |
| Response Rate and Profit/Response for Contol Five Test Cells Select image to enlarge |
Each group having a higher response to its respective promotion has a correspondingly lower average value per response. This example highlights a fundamental challenge in determining which case is the better one and which promotion should in turn be rolled out to a larger audience. Which test produced the best result for this example? Is a higher response rate better than a higher average order value? Or is the reverse better? (Or is there enough time and budget to void this test and try again, hoping for more easily read results?)
There is an approach which can help interpret these numbers and enable a reasonable sort order to identify the “best” promotion, an approach based on response and value. “Expected value” is defined as a probability of an outcome multiplied times the value of the outcome. If you were to bet $1 on the flip of a coin being “heads”, the expected value for each coin flip would be 50% – the likelihood of heads – times the value of the bet, $1, which is $0.50: 50% times $1, for a $1 bet on heads.
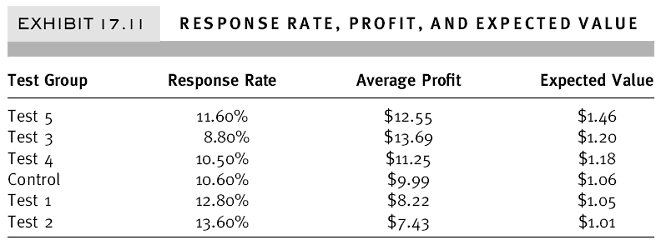
For promotional tests, the response rate can be treated as a probability and, when multiplied times the average response value, used to create “expected value.” The expected value for each test and control can then be sorted to identify the “best” offer, based on expected value, as shown below.
 |
|
Response Rate, Profit, and Expected Value |
In this example the “best” offer now appears to be Test 5, with expected value of $1.46, over Test 3, with expected value of $1.20. Test 3, even with the lowest response rate of 8.8%, does very well. Surprisingly, Test 2 is at the bottom of the list, with an expected value of $1.01, even with a response rate of 13.6%, which is more than 50% higher than the response rate of Test 3.
This first step is convenient but only partially answers the question, and in fact could provide very misleading conclusions. A wrong conclusion will generate incorrect expectations for profit from a rollout of one of these promotions to a large audience, and incorrect expectations will lead to a shortfall in profit against plan and potentially a missed opportunity if the best promotion is not identified..
Testing is usually done based on samples of the expected audience and not the complete target audience. The smaller groups are more cost-effective, particularly if more than one promotion can be tested in parallel, truly highlighting a “best” promotion from among several competing promotions. The use of audience samples, even if randomly chosen, demands that the results be interpreted from a statistical point of view, with different results generated by different samples. This is sampling error, meaning the results of a sample will not be the same as the results based on the entire audience.
This can be simulated easily enough. Assume a total audience of one million people and 25,000 – 2.5% – will respond to promotion X. If a sample of 1,000 people were selected, it might contain 25 of these responders, the same 2.5%.
In fact, a test of 10 such samples – each of 1,000 people – contained counts ranging from 16 to 33. These counts are equivalent to “test response rates,” which range from 1.6% to 3.3%. Having test results based on the sample with the smallest response rate of 1.6% would create an unintended 36% cushion against the true rate of 2.5% (2.5-1.6), good news as far as making business plan.
However, if the rollout estimate was based on the test group with the largest response rate, 3.3%, a 24% shortfall in the business plan would result – the difference of 2.5% actual against a plan of 3.3%.
To further complicate the interpretation of these results, sampling error is based on a single statistic, and the expected value created above is based on two different distributions – the proportion of people who responded relative to those who did not and the value of the purchases made by these responders.
There is a useful statistical test based on multiple samples such as these, a test known as the difference of means test. In this test, multiple sample results can be compared and interpreted based on expected variation between samples. This enables a marketer to identify multiple groups – test cells – whose results may be too similar to be accepted as distinct. In other words, small differences in results for some test cells means there was no discernible difference in the promotions for these cells from a response standpoint. When a single test cell is not statistically different from the control, the test is said to provide no discernible lift. The same can be said of multiple test cells whose results are also not statistically distinct from each other.
This statistical test is most easily interpreted graphically. As noted earlier, the statistic can be applied to response and average response value individually but not in combination (for expected value).
The following tables show a difference of means test applied first to response rate and then to average response value. The graphic bars on the left side of each table identify the test cells that are distinct from one another.
 |
 |
The first table shows Test 3 results are distinct, while Tests 4, control and 5 are “similar,” as are Tests 1 and 2. Since Tests 4 and 5 are no different from the control, the focus will be on Test 3 and Tests 1 and 2.
The second table shows that average response value for Tests 1 and 4 is not different from the control, while Test 2 is distinct and lower. Tests 5 and 3 are distinct and higher.
Combining these two interpretations with the expected value table provides a reasonable conclusion: On the high side, Tests 5 and 3 both are statistically relevant, Test 3 on both response rate and value. However, the expected value of Test 5 is so much higher than Test 3 – $1.46 over $1.20 – that even if response rate were 1% lower, the same as the control, the expected value of Test 5 would still be better – $1.33 – than Test 3, $1.20.
The most important point is that this approach will increase confidence in interpreting results and increase the likelihood that test results are repeatable outside the test situation. There is still a chance that results will not meet these expectations, but the chance is smaller, and the chance of making a wrong conclusion is smaller as well. If this situation of ambiguous results occurs too frequently, then it may be appropriate to increase the sample size of future tests to improve the level of differentiation between response groups.
Jeff LeSueur is the author of Marketing Automation, Practical Steps to More Effective Direct Marketing, published by John Wiley – Volume 10 in the Wiley and SAS Business Series.


